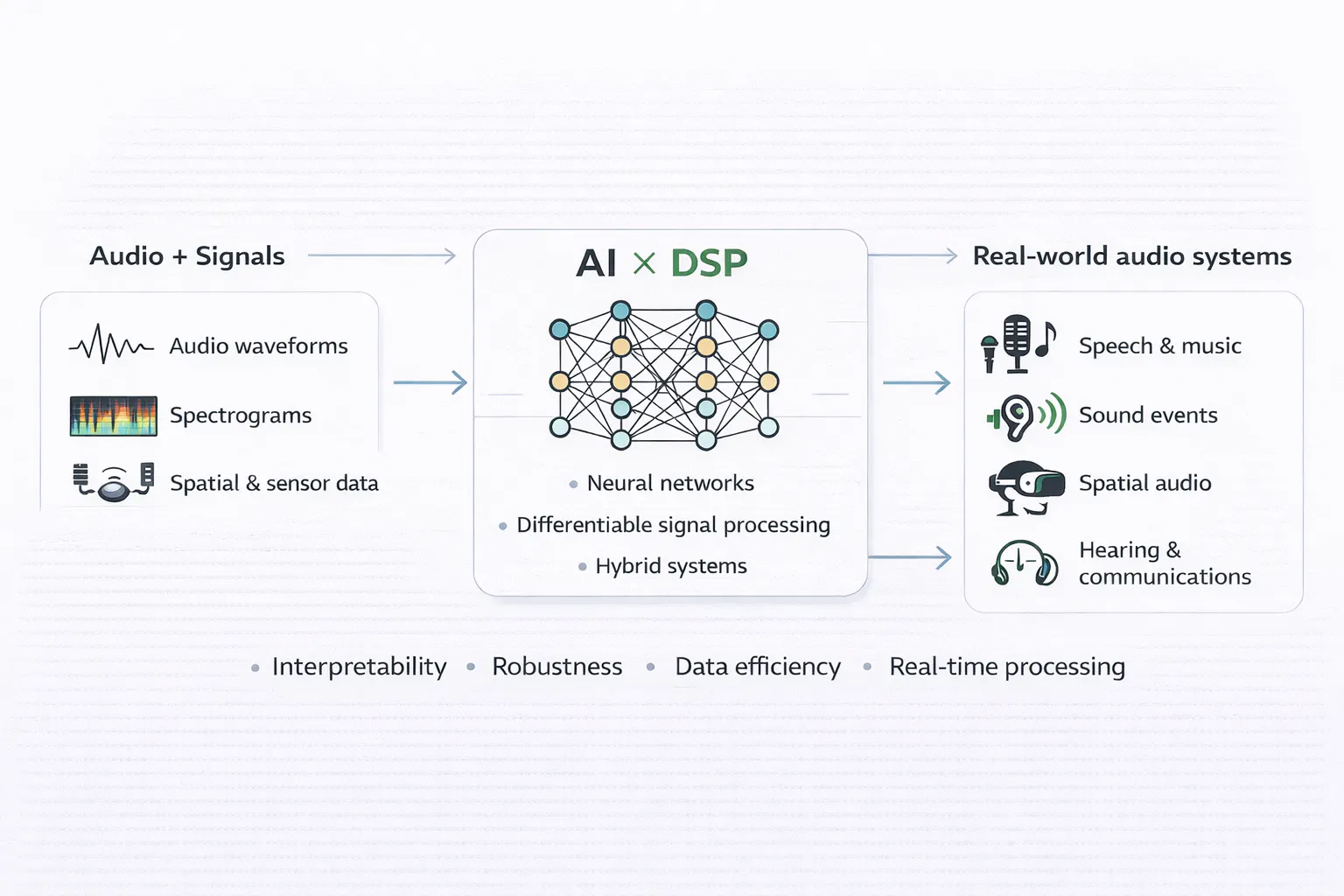
Від DSP до AI: еволюційні підходи в обробці аудіо
https://ift.tt/V8FTlqW
Вступ: аудіо як мова інтелекту першого рівня
Аудіо є одним із найбільш інформаційно насичених та чутливих до сприйняття каналів, через які люди взаємодіють із світом. На відміну від зору або тексту, аудіо є неперервним у часі, підпорядкованим фізичній акустиці та негайно оцінюваним людською слуховою системою з мілісекундною чутливістю. Ці властивості роблять аудіо унікально складним для систем штучного інтелекту. Навіть незначні спотворення — розриви фази, часовий розмазаність та спектральні артефакти — можуть призводити до зниження розбірливості, втоми слухача або втрати занурення.
Історично аудіо-системи будувалися на детерміністичній цифровій обробці сигналів (DSP). Ці системи опиралися на математично обґрунтовані інструменти, такі як фільтри, перетворення, адаптивні оцінювачі та фізичні моделі розповсюдження звуку. Методи DSP забезпечували стабільність, причинність і реальні часові гарантії, але їм було складно впоратися з дуже нестаціонарними сигналами, складними акустичними середовищами та семантичним розумінням.
Зі з’явою машинного навчання з’явилася принципово інша парадигма. Замість явного моделювання кожного акустичного явища системи з навчання виводять складні відповідності з даних. Ця зміна привела до великих проривів у розпізнаванні мови, зниженні шумів, створенні музики та моделюванні просторового аудіо. Проте ранні спроби повністю замінити DSP енд-то-енд нейронними мережами швидко показали обмеження. Чисто дані, що навчаються, моделі часто зазнавали невдач під час невідомих умов, порушували фізичні обмеження або вимагали обчислювальних ресурсів, несумісних із реальним часом.
Через це сучасний аудіо-інтелект переходить до гібридного підходу. У цьому контексті класична обробка сигналів пропонує структурні пріори, фізичне обґрунтування та системні гарантії, тоді як машинне навчання підвищує адаптивність, сприйняття та контекстуальне мислення. Аудіо AI тому — не просто застосунок загального ML, а домен, де інтелект потрібно інженерно впроваджувати у суворі часові, фізичні та перцепційні обмеження.
Ця стаття представляє систематичний, інженерний погляд на штучний інтелект у аудіо та обробці сигналів. Замість того, щоб бачити прогрес просто як заміну старих методів, вона показує, як DSP, машинне навчання та системна інженерія разом створюють ефективні, придатні в експлуатації системи. Кожен розділ досліджує основну виміри цієї конвергенції зі збереженням однакової глибини, що відображає збалансовану природу сучасних аудіо систем.
Засади класичної обробки сигналів в еру AI
Незважаючи на прогрес у машинному навчанні, класична обробка сигналів залишається базовою для аудіо інтелекту. Аудіо сигнали зчитуються з високою швидкістю, зазвичай в діапазоні від 44.1 кГц до 192 кГц, і їх потрібно обробляти неперервно без перерв. Це накладає суворі обчислювальні та архітектурні обмеження, які не можна ігнорувати. Теорія обробки сигналів надає інструменти, які дозволяють раціонально підходити до цих обмежень формально.
Одне з найглибших понять у обробці аудіо — це компроміс між часом та частотами. Представлення, такі як короткочасне перетворення Фур’є (STFT), збалансовують часову роздільну здатність із спектральною роздільною здатністю, такий компроміс безпосередньо впливає на якість звучання. Сприйняття людини чутливе як до тимчасових коливань, так і до гармонічної структури, тому дизайн представлення є критичним інженерним рішенням.
Стабільність та причинність також є надзвичайно важливими. Багато аудіо-додатків — телефония, конференції, автомобільні системи, доповнена реальність — вимагають причинної обробки з обмеженою затримкою. Алгоритми, що спираються на майбутні зразки або довгі контекстні вікна, можуть добре працювати офлайн, але непридатні для інтерактивних систем. DSP надає формальні гарантії, такі як стабільність із обмеженим вхідним та вихідним сигналами, що забезпечує передбачувану поведінку в будь-яких умовах експлуатації.
Обробка сигналів також кодує фізичні знання. Акустичне розповсюдження, реверберація та просторові підказки виникають з добре вивчених фізичних процесів. Ігнорування цих принципів часто призводить до моделей, які добре підганяються під навчальні дані, але катастрофічно не працюють при зміні умов. Структури DSP виступають як індуктивні упередження, спрямовуючи навчання до фізично правдоподібних рішень.
У епоху AI DSP не змагається з машинним навчанням; він обмежує та дозволяє йому діяти. Вбудовуючи primitives DSP у навчальні конвеєри, інженери зменшують потребу в зразках, підвищують надійність та забезпечують можливість розгортання. Ця основа є суттєвою для розуміння того, чому сучасні аудіо AI системи виглядають саме так.
Сприйняття аудіо та семантичне розуміння
Системи сприйняття аудіо націлені на витяг семантичного значення з звучання. Завдання як класифікація акустичної сцени, виявлення подій звучання та тегування аудіо дозволяють машинам інтерпретувати своє слухове середовище. Ці можливості критично важливі для застосунків від розумних пристроїв і нагляду до автономних систем та допоміжних технологій.
Більшість конвеєрів сприйняття починають із перетворення сирих сигналів у часово-частотні представлення. Лог-мел спектрограми популярні, бо їх легко використовувати та вони мають сенс для мозку. Глибокі нейронні мережі, зазвичай на основі згорткових або трансформерних архітектур, далі обробляють ці представлення. Ці мережі вчаться ієрархічним аудіо ознакам.
Значний прогрес у цій області принесли великомасштабні попередньо навчальні аудіо-моделі. Навчання на величезних, слабко позначених наборах даних дозволяє моделям вивчати загальні аудіо-представлення, які ефективно переносяться між задачами. Це зменшило потребу у задачево-специфічній інженерії ознак та покращило продуктивність у режимах з обмеженими даними.
Однак задачі сприйняття залишаються чутливими до переднього вибору, часового контексту та доменного збою. Різниця між мікрофонами, шумовими умовами та записними середовищами може суттєво впливати на продуктивність. Відтак системи сприйняття часто включають нормалізацію, розширення даних та стратегії адаптації до домену.
Важливо, що семантичне розуміння не знімає потреби у обробці сигналів. Часове вирівнювання, когерентність фази та компроміси роздільної здатності все ще впливають на поведінку моделі. Успішні системи сприйняття інтегрують навчені репрезентації у ретельно сконструйовані сигнал-пайплайни.
Розширення та відновлення аудіо
Розширення аудіо зосереджено на покращенні якості сигналу в умовах несприятливих середовищ. Типові завдання включають зниження шуму, де-реверберацію, допомогу у скасуванні відбиття електронних сигналів та компенсацію втрат пакетів. Такі системи зазвичай розгортаються у потокових процесах реального часу, де затримка та стабільність є критичними.
Розширення є особливо складним, адже помилки відразу відчуваються користувачем. Артефакти, такі як музичний шум, спотворення мови або часовий піск, погіршують досвід користувача та можуть знижувати розбірливість. На відміну від задач сприйняття, системи розширення повинні працювати причинно та безперервно.
Передбачайте наявність мови, створюйте спектральні маски або визначайте функції підсилення, в той час як компоненти DSP займаються відновленням звуку, об’єднанням аудіо-сегментів та усуненням артефактів. Моделі машинного навчання визначають наявність мови, створюють спектральні маски та встановлюють функції підсилення, тоді як компоненти DSP відповідають за відновлення звуку та комбінацію аудіо-сегментів. Таке розподілення праці дозволяє системам навчання зосередитися на висновках, забезпечуючи фізичну та перцепційну коректність DSP.
Обмеження за затримкою є найважливішим фактором у виборі дизайну. Щоб знайти правильний баланс між реактивністю та частотним розділенням, обираються розміри кадрів, кроки та буферизаційні стратегії. Нейронні моделі мають бути оптимізовані для потокових висновків, часто використовуючи причинні згортки або стан-реберкові архітектури.
Успіх систем розширення ілюструє ширшу тему аудіо AI: інтелект народжується не з заміни класичних методів, а з їх доповнення навчальним висновком у рамках суворих системних обмежень.
Виділення джерела та деміксування аудіо
Source separation має на меті розкласти аудіо суміш на її складові сигнали. Застосування включає розділення кількох промовців, видобуток музичних джерел та ізоляцію діалогу. Ці завдання є centrale для виробництва медіа, комунікацій та доступності.
Глибоке навчання значно покращило якість розділення, навчуючи складним пріорам джерел. Більшість систем працюють у часово-частотній області, оцінюючи маски, що ізолюють окремі джерела. Відновлення фази залишається центральною проблемою, оскільки лише амплітудне моделювання може вводити артефакти.
Гібридні підходи домінують у виробничих системах. Нейронні мережі оцінюють спектральні компоненти, тоді як DSP відповідає за синтез, узгодження фази та часову згладженість. Втручення на багатовимірних шкалах та перцепційні об’єкти часто використовуються для покращення якості.
Незважаючи на вражаючі чисельні показники, перцепційна оцінка залишається суттєвою. Системи розділення підкреслюють межі чисто об’єктивних вимірів і підкреслюють важливість оцінювання, згідного з людським сприйняттям у аудіо AI.
Просторове аудіо та моделювання акустичної сцени
Просторове аудіо розширює інтелект у тривимірний простір. Задачі включають локалізацію джерела звуку, спрямування променів, моделювання приміщення та захоплення вражаючого відтворення. Ці можливості є ключовими для AR/VR, автомобільних систем та передових медіа-досвідів.
Просторові підказки виникають із фізичної геометрії: міжканальний часовий розрив, різниці рівнів та спектральне забарвлення. Хоча нейронні мережі можуть вивчати відображення від багатоканалних сигналів до просторових параметрів, вони обмежені фізикою.
Сучасні просторові системи використовують AI для оцінки та адаптації, тоді як DSP відповідає за фільтрацію й рендеринг. Це зберігає фізичну послідовність, одночасно дозволяючи персоналізацію та обізнаність щодо середовища.
Генерація аудіо та диференційоване DSP
Генеративні аудіо системи створюють звук, а не аналізують його. Застосування включають тексту в мову, композицію музики та звукопроектування. Хоча енд-то-енд нейронна генерація досягла вражаючої реалістичності, їй часто бракує контролю та ефективності.
Диференційоване цифрове оброблення сигналів (DDSP) вирішує ці обмеження, прямо вбудовуючи моделі сигналів у нейронні мережі. Генератори, фільтри та обгортки стають навчальними компонентами, поєднуючи інтерпретованість із навчанням. DDSP демонструє гібридну філософію сучасного аудіо AI — навчання, яке діє всередині структурованих, фізично значущих моделей.
Пояснюваність, оцінювання та довіра
Коли аудіо AI-системи виходять у регульовані та критично безпечні сфери, пояснення та оцінювання стають необхідними. Техніки аудіо-специфічного XAI візуалізують внесок у часово-частотній площині, дозволяючи інженерам перевіряти поведінку моделі.
Оцінювання залишається складним через розрив між об’єктивними метриками та сприйняттям. Надійні системи поєднують сигнальні, перцепційні, завдань-залежні та випробувальні на стрес-режими оцінювання.
Надійність аудіо AI потребує прозорості, відтворюваності та узгодженості з людським сприйняттям.
Системна інженерія та майбутнє розумного аудіо
У кінцевому рахунку аудіо-інтелект — це проблема системної інженерії. Реальні часові обмеження, бюджет енергії та середовища розгортання формують кожне рішення. Успішні системи інтегрують DSP, AI та програмну інженерію в узгоджені конвеєри.
Майбутнє аудіо лежить у адаптивних, контекстуально обізнаних, пояснюваних системах, які працюють безшовно на різних пристроях та середовищах. Аудіо більше не пасивний сигнал — це розумний інтерфейс, який з’єднує людей та машини.
Посилання:
Steinmetz та ін. — «Audio Signal Processing in the Artificial Intelligence Era: Challenges and Directions»
Akman & Schuller — «Audio Explainable Artificial Intelligence: A Review» (Intelligent Computing)
McCarthy та ін. — «Machine Learning in Acoustics: A Review and Open-source Repository»
IEEE Signal Processing Magazine — «The Convergence of Machine Learning and Signal Processing…» (framing/editorial page)
Kong та ін. — «PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition»
Cobos та ін. — «An overview of machine learning and other data-based methods for spatial audio capture, processing, and reproduction»
HI-FI News
via HackerNoon https://hackernoon.com
16 лютого 2026 року, 12:40 PM
February 16, 2026 at 12:40PM
Залишити відповідь