Зустрічайте Мімі: нейронний аудіокодек, що живить наступне покоління розмовних LLM
image caption: Зображення з репозиторію Mimi на GitHub
Якщо ви нещодавно взаємодіяли з голосовим помічником на базі штучного інтелекту, ви могли помітити спільну обмеженість: вони часто виглядають як текстова модель, обгорнена у голосовий інтерфейс. За лаштунками звичайний конвеєр перетворює вашу вимову на текст, генерує текстову відповідь і повторює її вголос. Такий каскадний підхід втрачає нюанси людської мови та призводить до розчарувань через затримки.
Щоб досягти справжнього, людськоподібного голосового ШІ, моделі мають розуміти та генерувати мову нативно.
Уявляйте Мімі — сучасний нейронний аудіокодек, розроблений дослідницькою лабораторією штучного інтелекту Kyutai. Повністю з відкритим кодом Mimi заповнює прогалину між аудіо та текстом, поєднуючи семантичну та акустичну інформацію в дуже стислий потік дискретних токенів. Нижче — детальний розбір того, як працює Mimi, із реальними аудіо прикладами її можливостей реконструювання.
Що таке нейронний аудіокодек?
У своїй основі кодек стискає та розпаковує цифрові дані. У той час як традиційні помилкові кодеки, такі як MP3, видаляють дані, які важко почути людському вуху, нейронний аудіокодек використовує нейронні мережі для стискання та відтворення аудіосигналів.
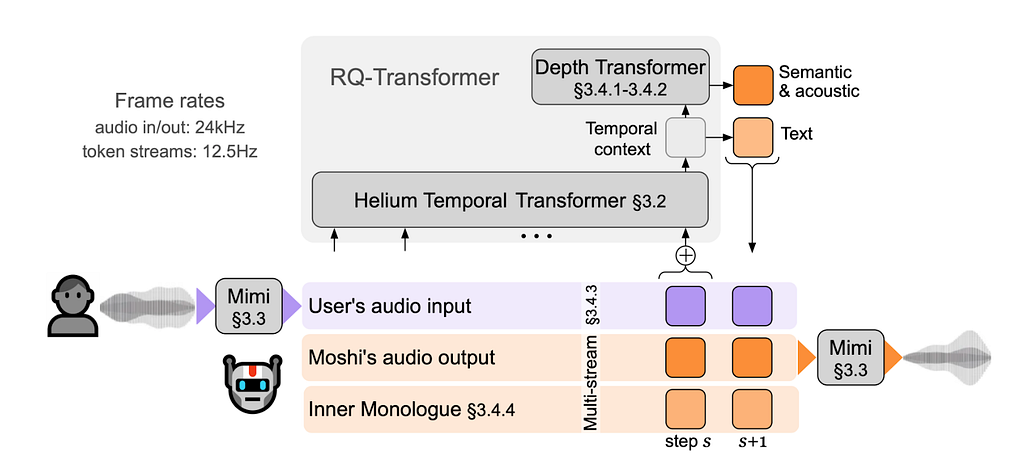
За допомогою архітектури типу енкодер–декодер з вузьким місцем (bottleneck) нейронні кодеки перетворюють сирі аудіо-вейви в стислий дискретний латентний простір (часто називають аудіо-токенами). Такий токенізований формат дозволяє великим мовним моделям (LLM) обробляти аудіо так само, як вони обробляють текстові слова.
Магія Mimi: характеристики та архітектура
Побудована на базі попередніх нейронних кодеків, таких як SoundStream та EnCodec, Mimi вводить кілька нових архітектурних та навчальних поліпшень.
Ось основні характеристики Mimi:
– Неймовірне стискання: Mimi обробляє аудіо з частотою 24 кГц і стискає його до представлення, яке працює лише на 12,5 кадрів за секунду (12,5 Гц).
– Надзвичайно низький бітрейт: досягає ефективного бітрейту 1,1 кбіт/с за допомогою використання 8 квантизаторів, кожен з яких дає 1 токен за кадр.
– Повністю потокове передавання: на відміну від деяких попередніх кодеків, Mimi є повністю каузальним. Це означає, що вона може кодувати та декодувати аудіо у безперервному потоці з затримкою всього 80 мс.
Головна інновація: семантичні та акустичні токени
Найбільша проблема під час навчання аудіо-LLM — зробити так, щоб згенерована мова була водночас зрозумілою та високої якості. Для цього моделі потребують семантичних токенів (які представляють лінгвістичний зміст) та акустичних токенів (які захоплюють стиль, голос та навколишнє середовище).
Зазвичай семантичні токени витягують за допомогою офлайн-каузальних моделей, як WavLM, що порушує можливість реального потокового передавання. Mimi вирішує це шляхом перенавчання: «переробляє» не каузальні семантичні знання з WavLM прямо в каузальний квантизатор під час навчання.
Щоб запобігти зниженню якості відтворення аудіо через семантичну інформацію, Mimi використовує хитрий підхід розділеної RVQ (Split Residual Vector Quantization). Вона ізолює семантичну інформацію в окремий перший квантізатор, тоді як паралельна 7-рівнева RVQ обробляє акустичні деталі. Це дозволяє Mimi отримати найкраще з обох світів: дуже виразне лінгвістичне розуміння та відмінну аудіо-якість.
Несподіваний трюк під час навчання: навчання лише за адверсаріальним сигналом
Під час розробки Mimi дослідники зробили несподіване відкриття. Традиційні кодеки використовують поєднання втрат відтворення (наприклад, збіг із оригінальним спектрограмом) та адверсаріальних втрат (за допомогою дискримінатора, щоб забезпечити реалістичність звучання аудіо) для навчання моделі.
Коли Kyutai усунув відтворювальну втрату й навчав Mimi використовуючи чисто адверсаріальне навчання, традиційні об’єктивні метрики (наприклад, VisQOL) знизилися, але якість аудіо з боку людини різко зросла. У суб’єктивних тестах прослуховування MUSHRA адверсаріальна лише стратегія дала помітний приріст, доводячи, що об’єктивні математичні метрики все ще погано відображають людське сприйняття аудіо.
Чому Mimi змінює правила гри для LLM
Поточні чатові LLM здебільшого призначені для обробки текстових токенів, які зазвичай надходять зі швидкістю близько 3–4 токенів на секунду. Привівши аудіо до частоти всього 12,5 Гц, Mimi надзвичайно зближує частоту кадрів аудіо з частотою кадрів тексту.
Це вирішує масштабну обчислювальну проблему. Замість того, щоб LLM потрібно було передбачати десятки тисяч сирих аудіодоріжок за секунду (що потребує величезних обчислень і шкодить взаємодії в реальному часі), потрібно передбачати лише кілька токенів аудіо Mimi.
Завдяки цьому Mimi успішно живить Moshi, прорывну модель Kyutai для реального часу, повноцінного діалогу в режимі повного взаємного обміну голосом. Завдяки токенізації Mimi Moshi може слухати та говорити одночасно без явного чергового розмежування говоріння, підтримуючи природну динаміку розмови, таку як переривання, реакція на підміну та емоційний тон — все з практичною затримкою всього 200 мс.
Висновок
Mimi представляє значний ривок у тому, щоб ІІ розумів аудіальний світ нативно. Майстерно розділивши семантичну та акустичну інформацію в ультранизькобітрейтний, повністю потоковий формат, вона відкриває потенціал для текстових LLM, щоб стати справжніми мультимодальними голосовими асистентами.
Найкраще те, що Mimi повністю з відкритим кодом і доступна розробникам на Hugging Face. Якщо ви хочете створити наступне покоління голосового ШІ, Mimi — ідеальне місце для початку.
Посилання та подальше читання
– Офіційний репозиторій GitHub (код та стек інференсу): github.com/kyutai-labs/moshi
– Demo Moshi & Mimi Live Interactive Demo: moshi.chat
– Важки моделі Mimi на Hugging Face: kyutai/mimi
– Офіційний технічний звіт: Défossez, A., та ін. (2024). «Moshi: модель-фонд для мови та тексту для реального часу діалогу». Доступний на arXiv.
– Блог Kyutai: «Нейронні аудіокодеки: як перенести аудіо в LLM» авторства Václav Volhejn. https://ift.tt/pLy7JrC
HI-FI News
via Towards AI – Medium
pub.towardsai.net
April 17, 2026, 06:41 AM
April 17, 2026 at 06:41AM
Залишити відповідь