Вартісна багатомовна транскрипція аудіо у масштабі за допомогою Parakeet-TDT та AWS Batch
https://ift.tt/D8iO2nc
Багато організацій архівують великі медіа-бібліотеки, аналізують записи контакт-центрів, готують навчальні дані для штучного інтелекту або обробляють відео за запитом для субтитрів. Коли обсяг даних значно зростає, витрати на керований сервіс автоматичного розпізнавання мови (ASR) швидко можуть стати основним обмеженням міркувань про масштабованість.
Щоб подолати цю проблематику витрат та масштабованості, ми використовуємо модель NVIDIA Parakeet-TDT-0.6B-v3, розгорнуту через AWS Batch на інстансах з апаратною прискореною роботою на GPU. Архітектура Token-and-Duration Transducer Parakeet-TDT одночасно передбачає текстові токени та їх тривалість, щоб розумно пропускати тишу та зайве оброблення. Це допомагає досягати швидкостей висновку, які на порядки швидші за реальний час. Платячи лише за короткі сплески обчислень, а не за повну довжину вашого аудіо, ви можете транскрибувати в масштабі за частку цента за годину аудіо, згідно з бенчмарками, описаними в цьому дописі.
У цьому дописі ми крок за кроком розглянемо побудову масштабованого, орієнтованого на події конвеєра транскрипції, який автоматично обробляє аудіофайли, завантажені до Amazon Simple Storage Service (Amazon S3), і покажемо, як використати Amazon EC2 Spot Instances та буферизований потоковий висновок, щоб Further зменшити витрати.
Можливості моделі
Parakeet-TDT-0.6B-v3, релізована в серпні 2025 року, є відкритою багатомовною моделлю ASR, яка забезпечує високу точність для 25 європейських мов з автоматичним виявленням мови та гнучким ліцензуванням за CC-BY-4.0. За оприлюдненими показниками NVIDIA модель зберігає помилку слова (WER) 6.34% у чистих умовах та 11.66% WER за 0 дБ SNR, і підтримує аудіо тривалістю до трьох годин за режиму локальної уваги. Серед 25 підтримуваних мов: болгарська, хорватська, чеська, датська, нідерландська, англійська, естонська, фінська, французька, німецька, грецька, угорська, італійська, латвійська, литовська, мальтійська, польська, португальська, румунська, словацька, словенська, іспанська, шведська, російська та українська. Це може зменшити потребу в окремих моделях або мовно-специфічній конфігурації під час обслуговування міжнародних європейських економік. Для розгортання на AWS модель потребує інстансів з підтримкою GPU з мінімальними 4 ГБ VRAM, хоча 8 ГБ забезпечують кращу продуктивність. Інстанси G6 (NVIDIA L4 GPUs) забезпечують найкраще співвідношення вартість/продуктивність для обчислювальних навантажень за нашими тестами. Модель також добре працює на G5 (A10G), G4dn (T4), а для максимальної пропускної здатності — на інстансах P5 (H100) або P4 (A100).
Архітектура рішення
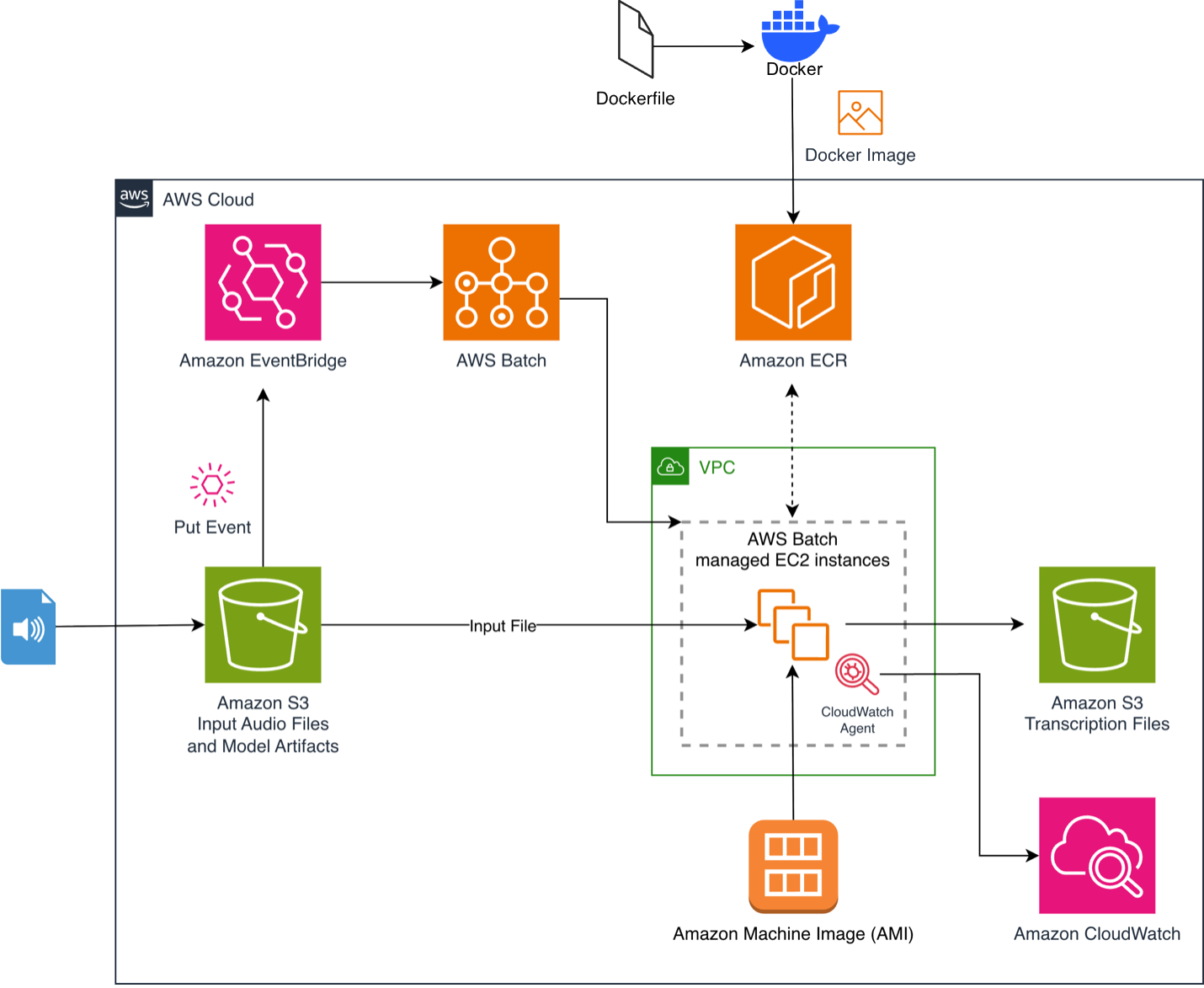
Процес починається, коли ви завантажуєте аудіофайл до бакету S3. Це запускає правило Amazon EventBridge, яке надсилає завдання до AWS Batch. AWS Batch надає обчислювальні ресурси з підтримкою GPU, а призначені інстанси витягують наш контейнерний образ із попередньо кешованою моделлю з Amazon Elastic Container Registry (Amazon ECR). Скрипт інференсу завантажує та обробляє файл, після чого завантажує на вихідний бакет S3 транскрипт у форматі JSON з часовими позначками. Архітектура масштабується до нуля під час простою, тому витрати виникають лише під час активного обчислення.
Для детального аналізу загальних компонент архітектури зверніться до нашого попереднього допису Whisper: транскрипція аудіо за допомогою AWS Batch та AWS Inferentia.
[Зображення 1. Архітектурна діаграма AWS, що показує конвеєр транскрипції аудіо за допомогою Docker, AWS Batch, EventBridge, ECR, S3 та CloudWatch.]
Необхідні попередні кроки
– Створіть обліковий запис AWS, якщо його ще немає, та увійдіть. Створіть користувача за допомогою AWS IAM Identity Center з повними адміністративними дозволами, як описано в Додаванні користувачів.
– Встановіть AWS Command Line Interface (AWS CLI) на локальний комп’ютер та створіть профіль для адміністратора, як описано у Налаштування AWS CLI.
– Встановіть Docker на локальному комп’ютері.
– Клонувати репозиторій GitHub на ваш локальний комп’ютер.
Побудова образу контейнера
У репозиторії міститься Docker-файл, який збирає спрощений образ контейнера, оптимізований для продуктивності висновку. Зображення базується на Amazon Linux 2023, встановлює Python 3.12 і під час збірки попередньо кешує модель Parakeet-TDT-0.6B-v3, щоб зменшити затримку завантаження під час виконання.
Pushing to Amazon ECR
У репозиторії є скрипт updateImage.sh, який визначає середовище (CodeBuild або EC2), збирає образ, створює репозиторій ECR за потреби, увімкнює перевірку на вразливості та відправляє образ. Запустіть його так: ./updateImage.sh
Розгортання рішення
Рішення використовує шаблон AWS CloudFormation (deployment.yaml) для provisioning інфраструктури. Скрипт buildArch.sh автоматизує розгортання, визначаючи ваш регіон AWS, збираючи дані про VPC, підмережі та групи безпеки, і розгортаючи стек CloudFormation:
./buildArch.sh
Під капотом це запускає:
aws cloudformation deploy –stack-name batch-gpu-audio-transcription \
–template-file ./deployment.yaml \
–capabilities CAPABILITY_IAM \
–region ${AWS_REGION} \
–parameter-overrides VPCId=${VPC_ID} SubnetIds=”${SUBNET_IDS}” \
SGIds=”${SecurityGroup_IDS}” RTIds=”${RouteTable_IDS}”
Шаблон CloudFormation створює середовище обчислень AWS Batch із інстансами GPU G6 та G5, чергу завдань, визначення завдання з посиланням на ваш образ ECR, входи та виходи S3-бакети з увімкненими сповіщеннями EventBridge. Він також створює правило EventBridge, яке запускає завдання Batch при завантаженні до S3, конфігурацію агента Amazon CloudWatch для моніторингу використання GPU/CPU/пам’яті та політики найменших привілеїв для ролей IAM. AWS Batch дозволяє вибирати зображення GPU Amazon Linux 2023, вказавши ImageType: ECS_AL2023_NVIDIA в конфігурації середовища обчислення.
Альтернативно ви можете розгорнути безпосередньо з консолі AWS CloudFormation, використовуючи посилання запуску, надане у README репозиторію.
Налаштування Spot інстансів
Amazon EC2 Spot інстанси можуть ще більше зменшити витрати, заповнюючи ваші навантаження не використаною потужністю EC2 із знижкою до 90% залежно від типу інстансу. Щоб увімкнути Spot інстанси, змініть середовище обчислення у deployment.yaml:
DefaultComputeEnv:
Type: AWS::Batch::ComputeEnvironment
Properties:
Type: MANAGED
State: ENABLED
ComputeResources:
AllocationStrategy: SPOT_PRICE_CAPACITY_OPTIMIZED
Type: SPOT
BidPercentage: 100
InstanceTypes:
– “g6.xlarge”
– “g6.2xlarge”
– “g5.xlarge”
MinvCpus: !Ref DefaultCEMinvCpus
MaxvCpus: !Ref DefaultCEMaxvCpus
# … залишок конфігурації без змін
Ви можете увімкнути це, встановивши параметр –parameter-overrides UseSpotInstances=Yes під час виконання aws cloudformation deploy. Стратегія розподілу SPOT_PRICE_CAPACITY_OPTIMIZED вибирає пули Spot-інстансів із найменшою ймовірністю переривання та найнижчою можливою ціною. Диверсифікація типів інстансів (G6 xlarge, G6 2xlarge, G5 xlarge) може покращити доступність Spot. Встановлення MinvCpus: 0 гарантує масштабування середовища до нуля під час простою, щоб уникнути витрат між завданнями. Оскільки ASR-завдання є безстанковими та ідемпотентними, вони добре підходять для Spot. Якщо інстанс буде відчужено, AWS Batch автоматично повторює завдання (налаштоване на до 2 повторні спроби у визначенні завдання).
Управління пам’яттю для довгого аудіо
Пам’ять моделі Parakeet-TDT збільшується лінійно з тривалістю аудіо. Швидкий кодер Conformer повинен згенерувати та зберегти ознаки для всього аудіосигналу, створюючи пряму залежність: подвоєння довжини аудіо приблизно подвоює використання VRAM. За словами карточки моделі, за повної уваги модель може обробляти до 24 хвилин за 80 ГБ VRAM.
NVIDIA вирішує це за допомогою режиму локальної уваги, який підтримує до 3 годин аудіо на 80 ГБ VRAM A100:
#Увімкнення локальної уваги для довгого аудіо
asr_model.change_attention_model(“rel_pos_local_attn”, [128, 128])
asr_model.change_subsampling_conv_chunking_factor(1) # автообрання
asr_model.transcribe([“input_audio.wav”])
Це може призвести до незначного зниження точності; рекомендуємо протестувати на вашому варіанті використання.
Буферизований потоковий висновок
Для аудіо тривалістю понад 3 години або щоб обробляти довге аудіо економічно на стандартному обладнанні, наприклад g6.xlarge, ми використовуємо буферизований потоковий висновок. Цю техніку запозичено з прикладу потокового висновку NVIDIA NeMo: обробка аудіо у перекриваючихся фрагментах, а не завантаження повного контексту у пам’ять.
Ми налаштовуємо 20-секундні фрагменти з 5 секундами лівого контексту та 3 секундами правого контексту, щоб підтримувати якість транскрипції на межах фрагментів (зверніть увагу: точність може зменшитися при зміні цих параметрів, тож експериментуйте, щоб знайти оптимальну конфігурацію. Зменшення chunk_secs збільшує час обробки):
#Streaming inference loop
while left_sample < audio_batch.shape[1]:
# додати зразки до буферa
chunk_length = min(right_sample, audio_batch.shape[1]) - left_sample
# [Логіка керування буфером та прапорами опущена для стисливості]
buffer.add_audio_batch_(...)
# Кодирувати за повним буфером [left-chunk-right]
encoder_output, encoder_output_len = asr_model(
input_signal=buffer.samples,
input_signal_length=buffer.context_size_batch.total(),
)
# Розшифрувати лише кадри чанку (постійне використання пам’яті)
chunk_batched_hyps, _, state = decoding_computer(...)
# Просунути рухоме вікно
left_sample = right_sample
right_sample = min(right_sample + context_samples.chunk, audio_batch.shape[1])
Обробка аудіо за фіксованими розмірами чанків відокремлює використання VRAM від загальної тривалості аудіо, дозволяючи одному інстансу g6.xlarge обробляти 10-годинний файл з тим самим використанням пам’яті, що й 10-хвилинний.
[Зображення 2. Рисунок 2. Буферизований потоковий висновок обробляє аудіо у перекриваючихся чанках з сталим використанням пам’яті.]
Щоб розгорнути з увімкненим буферизованим потоковим режимом, встановіть параметр EnableStreaming=Yes:
aws cloudformation deploy \
–stack-name batch-gpu-audio-transcription \
–template-file ./deployment.yaml \
–capabilities CAPABILITY_IAM \
–parameter-overrides EnableStreaming=Yes \
VPCId=your-vpc-id SubnetIds=your-subnet-ids SGIds=your-sg-ids RTIds=your-rt-ids
Тестування та моніторинг
Для перевірки ефективності рішення на масштабі ми провели експеримент із 1 000 однаковими 50-хвилинними аудіофайлами з NASA preflight crew news conference, розподіленими між 100 інстансами g6.xlarge, кожен обробляв 10 файлів.
[Зображення 3. Екран CloudWatch/Batch: 1 000 завдань у черзі batch-gpu-audio-transcription-jq з 100 паралельно працюючими демонстраційними завданнями.]
Розгортання включає конфігурацію агента Amazon CloudWatch для збору даних про використання GPU, споживану потужність, використання VRAM, використання CPU, пам’ять та дисковий простір з інтервалами оновлення 10 секунд. Ці метрики з’являються в просторі CWAgent, що дозволяє будувати панелі моніторингу в реальному часі.
Оцінка продуктивності та витрат
Щоб підтвердити ефективність архітектури, ми провели бенчмаркінг системи з використанням кількох довготривалих аудіофайлів.
Модель Parakeet-TDT-0.6B-v3 досягає сирої швидкості висновку 0.24 секунди на кожну хвилину аудіо. Проте повний конвеєр також включає накладні витрати на завантаження моделі в пам’ять, завантаження аудіо, попередню обробку входу та пост-обробку виходу. Через ці накладні витрати оптимізація витрат найкраще працює для довготривалого аудіо, щоб максимально використати час обробки.
Результати бенчмарку (g6.xlarge):
- Тривалість аудіо: 3 години 25 хвилин (205 хвилин)
- Загальна тривалість завдання: 100 секунд
- Ефективна швидкість обробки: 0.49 секунд за кожну хвилину аудіо
- Розбиття витрат
За цінами у регіоні us-east-1 для інстансу g6.xlarge ми можемо оцінити вартість за хвилину обробки аудіо.
Модель OPB
Модель оплати | Годинна вартість (g6.xlarge)* | Вартість за хвилину аудіо
On-Demand | приблизно $0.805 | $0.00011
Spot Instances | приблизно $0.374 | $0.00005
*Ціни є оцінками станом на час написання в регіоні us-east-1. Ціни Spot варіюються залежно від Availability Zone і можуть змінюватися.
Це порівняння підкреслює економічну перевагу самостійного підходу для великих завдань, що потребують масових транскрипцій порівняно з керованими API-сервісами.
Очистка
Щоб уникнути майбутніх витрат, видаліть ресурси, створені цим рішенням:
1) Очистіть усі S3-бакети (input, output та logs).
2) Видаліть стек CloudFormation:
aws cloudformation delete-stack --stack-name batch-gpu-audio-transcription
3) За бажанням, видаліть репозиторій ECR та образи контейнерів.
Для детальних інструкцій очищення зверніться до розділу очищення у README репозиторію.
Висновок
У цьому дописі ми продемонстрували, як побудувати конвеєр транскрипції аудіо, що обробляє аудіо у масштабі за частку цента за годину. Поєднуючи модель NVIDIA Parakeet-TDT-0.6B-v3 з AWS Batch та Spot інстансами EC2, ви можете транскрибувати 25 європейських мов з автоматичним визначенням мови та зменшити витрати порівняно з іншими рішеннями. Технологія буферизованого потокового висновку розширює цю можливість на аудіо різної тривалості на стандартному обладнанні, а подієва архітектура масштабовується автоматично від нуля до обробки змінних навантажень.
Щоб розпочати, ознайомтеся з прикладами коду в репозиторії GitHub.
https://github.com/aws-samples/sample-parakeet-transcription-awsbatch-nvidia-blog
Зміст підписані автори
Глеб Гейнке
Глеб Гейнке — архітектор глибокого навчання в Центрі інновацій штучного інтелекту генеративних технологій AWS. Глеб тісно співпрацює з корпоративними клієнтами для розробки та масштабування трансформаційних рішень генеративного ШІ для складних бізнес-завдань.
Джастін Лето
Джастін Лето — глобальний провідний архітектор рішень у команді Private Equity в AWS. Джастін є автором Data Engineering with Generative and Agentic AI on AWS, опублікованої APRESS.
Юсонг Ван
Юсонг Ван — провідний спеціаліст з високопродуктивних обчислень (HPC) та архітектор рішень у AWS з більш ніж 20 роками досвіду роботи в національних науково-дослідних установах та великих фінансових корпораціях.
Браян Магуайр
Браян Магуайр — провідний архітектор рішень в Amazon Web Services, зосереджений на допомозі клієнтам реалізовувати свої ідеї у хмарі. Браян — співавтор книги Scalable Data Streaming with Amazon Kinesis.
HI-FI News
через Штучний інтелект https://aws.amazon.com/blogs/machine-learning/
22 квітня 2026 р. о 23:08
April 22, 2026 at 11:08PM
Залишити відповідь