З мелових спектрограм до аудіо-токенів: архітектурна зміна, яка зробила можливим GPT-4o Realtime
Якщо ви користувалися GPT-4o Realtime, Gemini Live або Moshi і замислювалися, чому вони відчуваються інакше, ніж голосові помічники, з якими ви зросли, відповідь не в тому, що моделі більші або GPUs швидші. Відповідь у тому, що представлення вхідних даних змінилося. Ера тридцятирічних мел-спектрограм закінчується, і на зміну їй приходить нове представлення — навчені дискретні аудіо-токени. Ця зміна є архітектурною причиною того, чому аудіо LMs можуть переривати розмову природньо, чому затримка з середнім значенням нижче 500 мс, і чому «ASR потім LLM потім TTS» стане застарілою конвеєрною лінією до 2027 року.
Цей допис — огляд того, що саме за зміною стоїть насправді, чому це зайняло стільки часу, та що це змінює для систем розпізнання мови та синтезу, які ви зараз будуєте.
The thirty-year mel spectrogram era
Возьміть будь-яке висловлення мови. Зніміть його із швидкістю 16 кГц. У вас виходять 16 000 чисел на секунду, що занадто багато для прямого оброблення моделлю. Стандартний крок, який використовується майже в кожній системі мовлення з 1990 по 2023 рік, — стискати цю сирцеву сигнал у мел-спектрограму: двовимірна матриця, де одна вісь — час (близько 100 кадрів за секунду), інша — частота (близько 80 мел-розподілених бінів). Кожна клітинка — дійсна числова енергія.
Це представлення є неперервним (вещева енергія), перцептивно мотивованим (мел-призначення відповідає людському слуху) і приблизно у 200 разів меншим за сирувий звук. Whрісер приймає його. wav2vec 2.0 приймає його. SpeechT5 виробляє його. Архітектура Conformer побудована навколо нього. Уся література ASR та TTS за три десятиліття припускала мел-спектрограми як робоче представлення.
Mel-спектрограми чудові для однієї задачі за раз. Вони жахливі для іншої проблеми: синтезу розуміння та генерації мови в одну модель, яка думає так, як LLM. Причина така: LLM є авторегресивними предикторами наступного токена по дискретних словарях. Мел-функції — це неперервні числа. Ви не можете попросити LLM «згенерувати наступний мел-кадр» так само, як ви просите згенерувати наступне слово, не додаючи окремий декодер, що руйнує елегантність авторегресивної конструкції та знову вводить усі проблеми ланцюгового конвеєра.
Протягом трьох десятиліть це не було проблемою, вартою вирішення, бо у аудіо не існувала парадигма авторегресивного LLM. Потім вона з’явилася.
The neural codec breakthrough
Три публікації за два роки радикально змінили представлення входу для мовної інтелектуальної системи назавжди.
SoundStream (Zeghidour et al., Google, 2021) навчав нейронний аудіо-кодек, який стискав мову приблизно до 75 дискретних токенів на секунду на кодове бюро, через кілька залишкових кодбуків, з відтворювальною якістю, конкурентною традиційним кодекам як Opus за набагато нижчих бітрейтах. Головна інновація — вузьке місце резидуального векторного квантування (RVQ): замість одного дискретного словника, кілька словників працюють із різними роздільностями, кожен уточнюючи залишковий сигнал попереднього. Результат — токенізатор, який генерує послідовність, придатну для LLM, збережуючи акустичну вірність.
EnCodec (Défossez et al., Meta, 2022) вдосконалив ту саму ідею і випустив відкриті ваги з сильною якістю реконструкції при 6 kbps і нижче. EnCodec став де-факто типовим аудіо-токенайзером для відкритої дослідницької спільноти.
AudioLM (Borsos et al., Google, 2022) показав, що як тільки у вас є добрий аудіо-токенайзер, ви можете навчити простий авторегресивний трансформер моделювати аудіо так само, як GPT-моделі текст. Модель приймає короткий аудіо-подати і продовжує його, генеруючи зрозумілу мову, музику та навіть невербальні звуки. Це була демонстрація концепції, що кодек-токени плюс LLM насправді працюють.
З 2023 року нейронні аудіо-кодеки розповсюдились. Поточний фронтир — одно-потокові кодеки з низьким токен-рейтом, розроблені спеціально як вхід для аудіо-LMs.
Mimi від Kyutai особливо вартий уваги. Він працює на 12.5 Гц, що означає 12.5 токенів аудіо за секунду на кожен кодбук. З 8 кодбуками це 100 токенів на секунду, щоб репрезентувати мову, що відповідає приблизно такому ж порядку токенів, як англійський текст (близько 3–5 токенів за слово, ~10–15 слів за секунду вимови, отже ~30–75 текстових токенів за секунду усної мови). Це той момент, коли «аудіо — це просто ще один потік токенів» стає буквально правдою.
What discrete tokens unlock
Як тільки аудіо стає цілісним потоком дискретних токенів із працездатним темпом, з’являються три речі, які раніше були надзвичайно важкими.
1. Повноцінний авторегресивний аудіогенератор
Ви можете навчити трансформер прогнозувати наступний аудіо-токен, так само, як ви тренуєте LLM прогнозувати наступний текстовий токен. Без окремого декодера, без двоступеневої архітектури, без голови із безперервним виходом. Такі можливості продемонстрували AudioLM, VALL-E та MusicGen для одноразової генерації. Саме Moshi продемонстрував це для реального діалогу в режимі реального часу.
2. Спільне моделювання тексту та аудіо
Якщо й текст, і аудіо є потоками токенів, їх можна об’єднати. Один трансформер може приймати «користувач говорить, модель думає текстом, модель видає мову» без конвертацій між представленнями. Це архітектура за GPT-4o Realtime, де модель — це єдиний мультимодальний LLM, який обробляє аудіо всередину, мислить текстом і видає аудіо як один потік.
3. Повноцінна двостороння бесіда
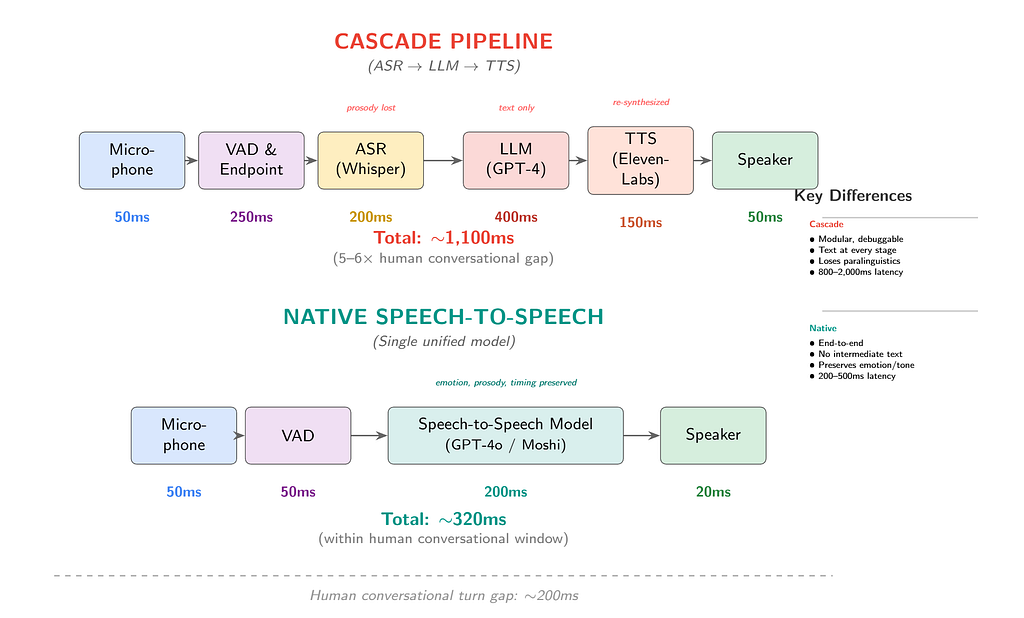
Найцікавіший трюк Moshi полягає в тому, що вона подає два аудіо-токени паралельно: потік користувача та потік асистента. Модель одночасно обробляє обидва. Це означає, що вона може слухати та говорити одночасно, природньо обробляти переривання, заповнювати «мхм»/«правильно» та слідувати дійсному двосторонньому ритму. Ніщо з цього не можливо з каскадною архітектурою ASR → LLM → TTS, бо каскад за визначенням працює по черзі.
Why this took so long
Справді справедливо запитати: чому це зайняло так довго? Авторегресивна революція LLM почалася у 2017 році. Mel-спектрограми були відомим обмеженням щонайменше десятиліття. Чому дискретні аудіо-токени дійшли до практичності лише у 2022 році?
Разом зійшлося три причини.
– По-перше, аудіо складніше токенізувати, ніж текст. Текст попередньо розбитий на слова; аудіо — це неперервна хвиля з відсутніми чіткими одиницями. Попередні спроби до 2020 року використовували ручне кластеризаційність (акустичні одиниці, фонемні кодбуки), які втрачали забагато інформації для високоякісної генерації. Нейронні кодеки, навчені енд-ту-енд з RVQ та зворотніми втрати, стали проривом, що забезпечив як низьку швидкість токенів, так і високу якість реконструкції.
– По-друге, обчислювальний бюджет для аудіо-LMs значно вищий за відповідний текстовий, бо довжина послідовності більша. Однієї секунди мови — це 12.5 до 75 аудіо-токенів; той же контент як текст — близько 10 токенів. Поки витрати на увагу з великим контекстом не впали (FlashAttention, grouped-query attention, multi-codebook parallelism), аудіо-LMs були дослідницькими curiosities, а не продакшн-системами.
– По-третє, навчальні дані не існували в масштабах до останнього часу. Аудіо-LMs потрібні мільйони годин парних мовлення-текстових даних для ефективного навчання. Публічні набори даних (LibriSpeech, Common Voice, FLEURS) малі порівняно з потребами. Закриті лабораторії вирішували це за рахунок приватних колекцій; відкрита спільнота все ще наздоганяє.
What this means for the systems you’re building
Якщо ви випускаєте голосового агента у 2026 році, швидше за все, ви досі хочете каскадний конвеєр (VAD → ASR → LLM → TTS). Відкриті аудіо-LMs ще не конкурентні у використанні інструментів, викликах функцій або доменних знаннях. Затримка хороша; глибина мислення — ні. Потрібно дочекатися кінця 2026 або 2027 року, щоб розраховувати на чистий аудіо-LM для складного агента.
Але архітектурне рішення щодо ізоляції від цього має значення зараз. Два рекомендації.
– Розглядати межу speech-in / speech-out як межу моделі, а не межу компонентів. Якщо ваш агент розробляє так, що «вихід ASR» і «вхід TTS» — це читаємі текстові рядки, що передаються між контейнерами, ви знайдете, що ця припущення розвалюється при міграції на аудіо-LM. Краще: проектуйте агента навколо одного конверсійного стану, який експонує вхід мовлення, вихід слухання та проміжне мислення, і дозволяйте реалізації за цим інтерфейсом еволюціонувати від каскаду до аудіо-LM без зміни вашого кодексу застосунку.
– Не будувати глибокі залежності від проміжних текстових артефактів. Якщо ваша система потребує отримати буквальний транскрипт того, що сказав користувач для логування, аналітики чи модерації, зробіть це паралельно, опційно та відокремлено від основного циклу відповіді. Чисті аудіо-LMs можуть не створювати або проходити через чистий транскрипт; вони можуть видавати звук безпосередньо. Проєктуйте спостережність так, щоб не вимагати транскрипт — це виправданий ризик для наступного покоління архітектури.
The architectural change isn’t bigger models or better fine-tuning. It’s that speech became a token stream. Every downstream consequence flows from that single representational decision.
Архітектурна зміна полягає не в більших моделях або кращому тонкому налаштуванні. Справа в тому, що мова стала потоком токенів. Усі подальші наслідки базуються на цьому одному репрезентативному рішенні.
The summary
– Зміна: мовленнєва штучна інтелект moving від безперервних мел-спектрограм до дискретних нейронних токенів кодеків (SoundStream → EnCodec → Mimi / SNAC).
– Чому це важливо: дискретні токени дозволяють моделювати мову за тим же авторегресивним трансформером, що й текстові LLM. Досягається генерація аудіо end-to-end, спільне моделювання тексту та аудіо, та повноцінна двостороння розмова.
– Що вже випускається: Moshi (Kyutai), GPT-4o Realtime (OpenAI), Gemini Live (Google), наступні хвилі аудіо-LMs від Anthropic та Meta.
– Терміни: каскадні конвеєри залишаються основним за замовчуванням у продакшн до 2026 року. Аудіо-LMs стануть основним вибором для затримко-чутливих застосунків до 2027 року.
– Що робити зараз: проектуйте абстракції агента так, щоб межа speech-in / speech-out була межою моделі, а не компонентів. Не створюйте жорсткі залежності від проміжних транскриптів.
Going deeper
Це один розділ дев’ятої глави моєї книги про мовне AI для практиків. Розділ детально проходить шлях codec-лінії (SoundStream, EnCodec, Mimi, SNAC), потім архітектури аудіо-LM, які їх споживають (AudioLM, VALL-E, MusicGen, Moshi), з практичним нотбуком, що запускає Qwen2-Audio-7B на 4-біт на GPU 16 ГБ, щоб ви могли бачити аудіо-токени безпосередньо. Глава 11 розглядає, що ця трансформація означає для інженерії голосових агентів у режимі реального часу.
Book landing page · Open-source companion code · Paperback · Hardcover · Audiobook
Якщо цей есе був корисний, найпростіший спосіб підтримати більше подібних матеріалів — поділитися ним або придбати копію. Коментарі, виправлення та розбіжності вітаються.
HI-FI News
via DataDrivenInvestor – Medium
Примітка: текст переведено з оригіналу на Medium DataDrivenInvestor. Джерело: посилання нижче.
June 15, 2026 at 03:48AM
Залишити відповідь